
 公告:
公告:如何下载和可视化你的Twitter网络

作者|Steve Hedden编译|VK来源|Towards Data Science原文链接:https://towardsdatascience.com/how-to-download-and-visualize-your-twitter-network-f009dbbf107b
社会网络分析(SNA)本身就是一个非常有趣的研究领域,同时也是数据科学家应用于其他领域的有用技能。
在本教程中,我们将使用一个Python包Tweepy从twitter api下载Twitter数据,并使用另一个Python包NetworkX从该数据构建一个网络并运行一些分析。最后我们将使用Gephi来可视化网络。
什么是SNA
根据维基百科:
社会网络分析(SNA)是利用网络和图论研究社会结构的过程。它以节点(网络中的个体参与者、人或事物)以及连接它们的纽带、边或链接(关系或交互)来表征网络结构。
它已经进入了几乎所有的领域——同样,根据维基百科:
社会网络分析已经成为现代社会学的一项关键技术。它在人类学、生物学、人口学、传播学、经济学、地理学、历史学、信息科学、组织学、政治学、公共卫生、社会心理学、发展研究、社会语言学等领域也有重要的研究成果,和计算机科学,现在作为消费者工具普遍可用(见SNA软件列表)。
本教程的计划
- 使用Tweepy为我的所有好友和(大多数)他们的好友搜索Twitter
- 从所有这些连接创建一个数据帧
- 使用NetworkX从这些数据中提取网络并运行一些基本的网络分析
- 在Gephi可视化网络
Twitter提供了一个免费的rest api来实时流式传输数据,并批量下载历史数据。
杰米·佐尔诺扎已经写了一些关于使用API进行流式传输和下载数据的很好的教程:
https://medium.com/@jaimezornoza/downloading-data-from-twitter-using-the-streaming-api-3ac6766ba96c
https://towardsdatascience.com/downloading-data-from-twitter-using-the-rest-api-24becf413875
首先,我们将使用我的个人Twitter帐户(@stevehedden)建立一个网络。为了做到这一点,我们将首先列出我所有的粉丝(大约450人)。然后我们会找到这450个账户的所有粉丝。为了节省时间,对于拥有5000多名追随者的账户,我只会爬取他们的前5000名追随者。
首先,我们需要导入Tweepy和pandas。
import tweepy
import pandas as pd然后需要输入我们的twitterapi凭证。如果你还没有这些,你需要去https://apps.twitter.com/和创建应用程序。创建应用程序后,转到密钥和令牌获取令牌。
consumer_key = XXXXXXXXXXXXX
consumer_secret = XXXXXXXXXXXXX
access_token = XXXXXXXXXXXXX
access_token_secret = XXXXXXXXXXXXX使用Tweepy,我们可以使用这些凭据连接到twitter api并开始下载数据。
下面的代码只是使用上面输入的凭据连接到API。因为我们将要下载相当大的数据集,所以在初始化API时指定一些参数是很重要的。我们将wait_on_rate_limit和wait_on_rate_limit_notify设置为True。
从Twitter下载数据时有速率限制-在给定的时间范围内,只能向API发出有限数量的下载请求。通过将这些参数设置为True,我们不会在达到这些限制时中断与API的连接。相反,我们只需等到超时结束,就可以继续下载数据。
auth = tweepy.OAuthHandler(consumer_key, consumer_secret)
auth.set_access_token(access_token, access_token_secret)
api = tweepy.API(auth, wait_on_rate_limit=True, wait_on_rate_limit_notify=True, compression=True)为了开始数据下载,我们将从单个用户获得所有关注者。要得到这个,你需要用户的ID。如果你使用下面的代码知道某个用户的屏幕名称,则可以获取该用户的用户ID。
me = api.get_user(screen_name = ‘stevehedden’)
me.id我的用户名是:1210627806。
网络由节点(或顶点)和链接(或边)组成。对于这个网络,我们将使用单独的用户帐户作为节点,使用粉丝作为链接。因此,我们的目标是创建一个包含两列的用户id的边缘数据帧:source和target。对于每一行,目标跟随源。首先,我们要把我所有的粉丝都列为目标。
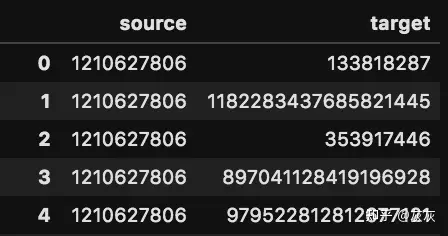
上面的屏幕截图显示了我们要创建的数据帧的结构。第一列source是我的用户ID(1210627806),第二列target是我的追随者。
下面的代码创建了450个关注者的列表。
user_list = ["1210627806"]
follower_list = []
for user in user_list:
followers = []
try:
for page in tweepy.Cursor(api.followers_ids, user_id=user).pages():
followers.extend(page)
print(len(followers))
except tweepy.TweepError:
print("error")
continue
follower_list.append(followers)现在我们有了所有粉丝的列表,我们可以把他们放到一个数据帧中。
df = pd.DataFrame(columns=[source,target]) 空数据帧
df[target] = follower_list[0] 将follower列表设置为目标列
df[source] = 1210627806 将我的用户ID设置为源但这不是一个很有趣的网络。为了可视化这个简单的网络,我们可以使用NetworkX包将数据帧转换成图形或网络。
import networkx as nx
G = nx.from_pandas_edgelist(df, source, target) df转换为图形
pos = nx.spring_layout(G) 指定视觉效果的布局然后我们使用matplotlib绘制图形。
import matplotlib.pyplot as plt
f, ax = plt.subplots(figsize=(10, 10))
plt.style.use(ggplot)
nodes = nx.draw_networkx_nodes(G, pos,
alpha=0.8)
nodes.set_edgecolor(k)
nx.draw_networkx_labels(G, pos, font_size=8)
nx.draw_networkx_edges(G, pos, width=1.0, alpha=0.2)上面的代码呈现了以下视觉效果。
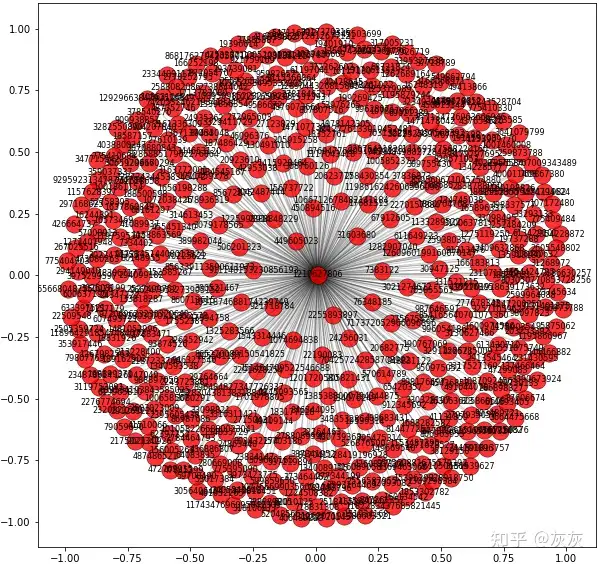
我们真正想要的是得到这450个用户的所有粉丝。为此,我们将遍历所有450个用户的列表,获取他们的粉丝,并将这些链接添加到原始数据帧。由于速率限制,这段代码需要很长时间才能运行。
user_list = list(df[target]) 使用我们在上面代码中提取的关注者列表,即我的450个关注者
for userID in user_list:
print(userID)
followers = []
follower_list = []
获取用户
user = api.get_user(userID)
获取追随者数量
followers_count = user.followers_count
try:
for page in tweepy.Cursor(api.followers_ids, user_id=userID).pages():
followers.extend(page)
print(len(followers))
if followers_count >= 5000: Only take first 5000 followers
break
except tweepy.TweepError:
print("error")
continue
follower_list.append(followers)
temp = pd.DataFrame(columns=[source, target])
temp[target] = follower_list[0]
temp[source] = userID
df = df.append(temp)
df.to_csv("networkOfFollowers.csv")此代码与上面的代码非常相似,它获取给定用户ID的所有关注者。主要区别在于,我们不是只输入一个帐户,而是在所有450个关注我的帐户中循环。另一个区别是,如果一个帐户有超过5000个关注者,我们只考虑前5000个关注者。这是因为API的工作方式。每个API请求只返回5000个帐户。因此,如果我们想从一个拥有,比如说,一百万追随者的帐户中获得所有粉丝,我们需要发出200个请求。
由于速率的限制,我让它运行了一夜以获取所有的数据。它发出15个API请求,然后必须等待15分钟,然后再发出15个请求,依此类推。所以要花很长时间。
一旦运行完成,你应该有一个包含网络所有边的csv。我把这些都写进了csv文件。
现在读取csv并使用NetworkX将df转换为图形。
df = pd.read_csv(networkOfFollowers.csv) 读入数据框
G = nx.from_pandas_edgelist(df, source, target)一旦数据转换成图形,我们就可以运行一些基本的网络分析。
G.number_of_nodes() 查找此图中的节点总数我的网络有716653个节点!
我们还可以使用中心性度量来找到网络中最有影响力的节点。最简单的中心性度量是度中心性,它是每个节点拥有的连接数的函数。下面的代码查找每个节点的连接数,即每个节点的次数,并按降序排列。
G_sorted = pd.DataFrame(sorted(G.degree, key=lambda x: x[1], reverse=True))
G_sorted.columns = [‘nconst’,’degree’]
G_sorted.head()我的网络中度最高的节点是节点37728789或@TheSolarCo。TheSolarCo的度是5039。其中5000个连接是我们爬下的5000个粉丝。但这意味着还有39个额外的联系——这意味着TheSolarCo关注了39个关注我的账户
要获取给定用户ID的帐户的用户名,请使用以下代码,类似于上面获取用户ID的方式。
u = api.get_user(37728789)
u.screen_name因为现在网络太大了(超过70万个节点),任何分析都需要很长时间才能运行,任何可视化都将是一团乱。
在本教程的其余部分中,我们将把网络过滤到更易于管理的节点数。我们使用NetworkX的k_core函数来实现这一点。k_core函数过滤出度数小于给定数字k的节点。在本例中,我将k设置为10,这将图中的节点数减少到大约1000个。
G_tmp = nx.k_core(G, 10) 排除度小于10的节点通过这个较小的图表,我们可以轻松地进行一些网络分析。我们首先使用社区检测算法将图分成若干组。
from community import community_louvain
partition = community_louvain.best_partition(G_tmp)
将分区转换为数据帧
partition1 = pd.DataFrame([partition]).T
partition1 = partition1.reset_index()
partition1.columns = [names,group]既然网络变小了,我们需要再次运行度中心代码。
G_sorted = pd.DataFrame(sorted(G_tmp.degree, key=lambda x: x[1], reverse=True))
G_sorted.columns = [names,degree]
G_sorted.head()
dc = G_sorted现在我们已经将节点分为多个组和每个节点的度,我们将它们组合到一个数据帧中。
combined = pd.merge(dc,partition1, how=left, left_on="names",right_on="names")现在你的数据帧应该是这样的。
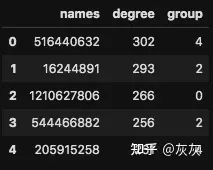
现在我们可以使用下面的代码来可视化这个图。
pos = nx.spring_layout(G_tmp)
f, ax = plt.subplots(figsize=(10, 10))
plt.style.use(ggplot)
cc = nx.betweenness_centrality(G2)
nodes = nx.draw_networkx_nodes(G_tmp, pos,
cmap=plt.cm.Set1,
node_color=combined[group],
alpha=0.8)
nodes.set_edgecolor(k)
nx.draw_networkx_labels(G_tmp, pos, font_size=8)
nx.draw_networkx_edges(G_tmp, pos, width=1.0, alpha=0.2)
plt.savefig(twitterFollowers.png)这将创建类似于这样的图形。

还是一团糟。我确信有一些方法可以使用matplotlib使可视化效果更好,但此时,我将文件导出为csv格式,并使用Gephi进行可视化。
Gephi是一个开源的网络分析和可视化软件。你应该能从他们的网站上下载安装它。它非常容易创建一些漂亮的视觉效果。如果你从未使用过Gephi,那么这里有一个很好的入门教程:
https://medium.com/u/f41b88c25359?source=post_page-----f009dbbf107b--------------------------------
要使用Gephi,首先需要将节点列表和边列表导出为csv文件。
combined = combined.rename(columns={"names": "Id"}) 我发现Gephi非常喜欢将节点列命名为Id
edges = nx.to_pandas_edgelist(G_tmp)
nodes = combined[Id]
edges.to_csv("edges.csv")
combined.to_csv("nodes.csv")你可以按照我上面提到的Gephi教程将这些文件导入Gephi并开始可视化你的网络。这是我的成果。
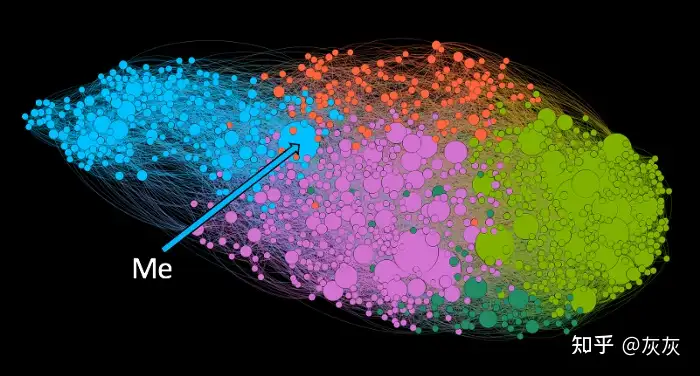
祝你好运!





